This post presents "Voice Separation with an Unknown Number of Multiple Speakers", a deep model for multi speaker voice separation with single microphone.
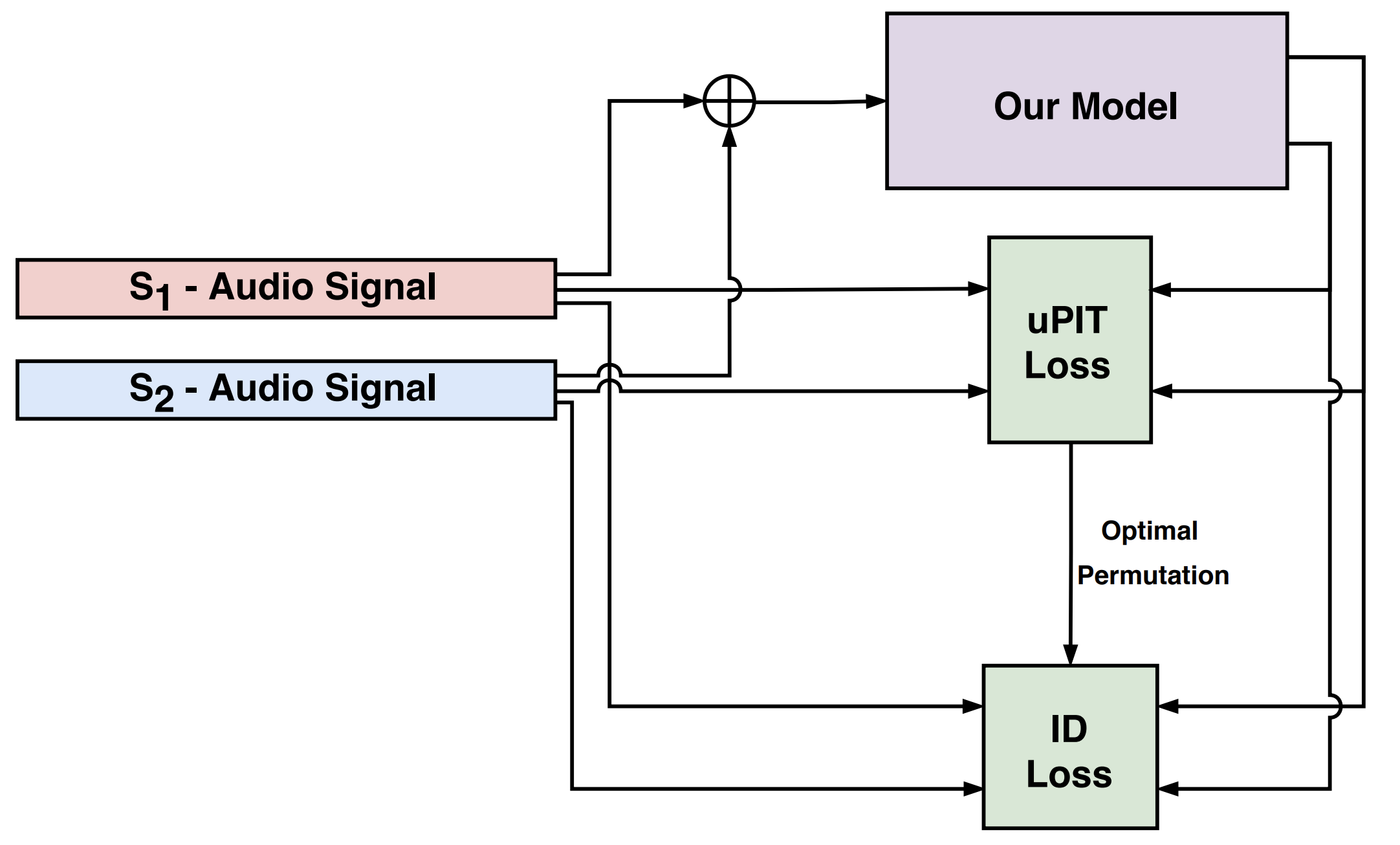
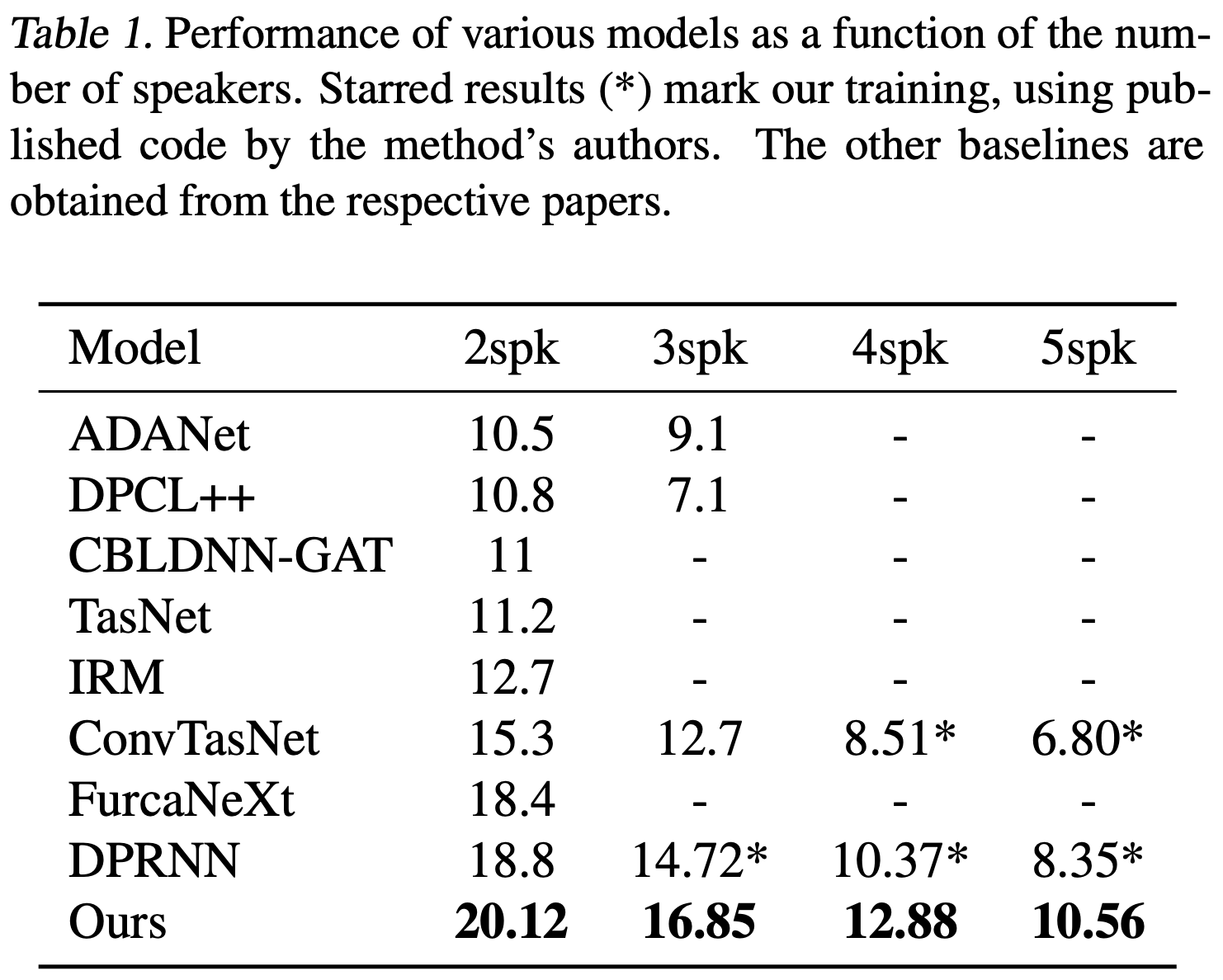
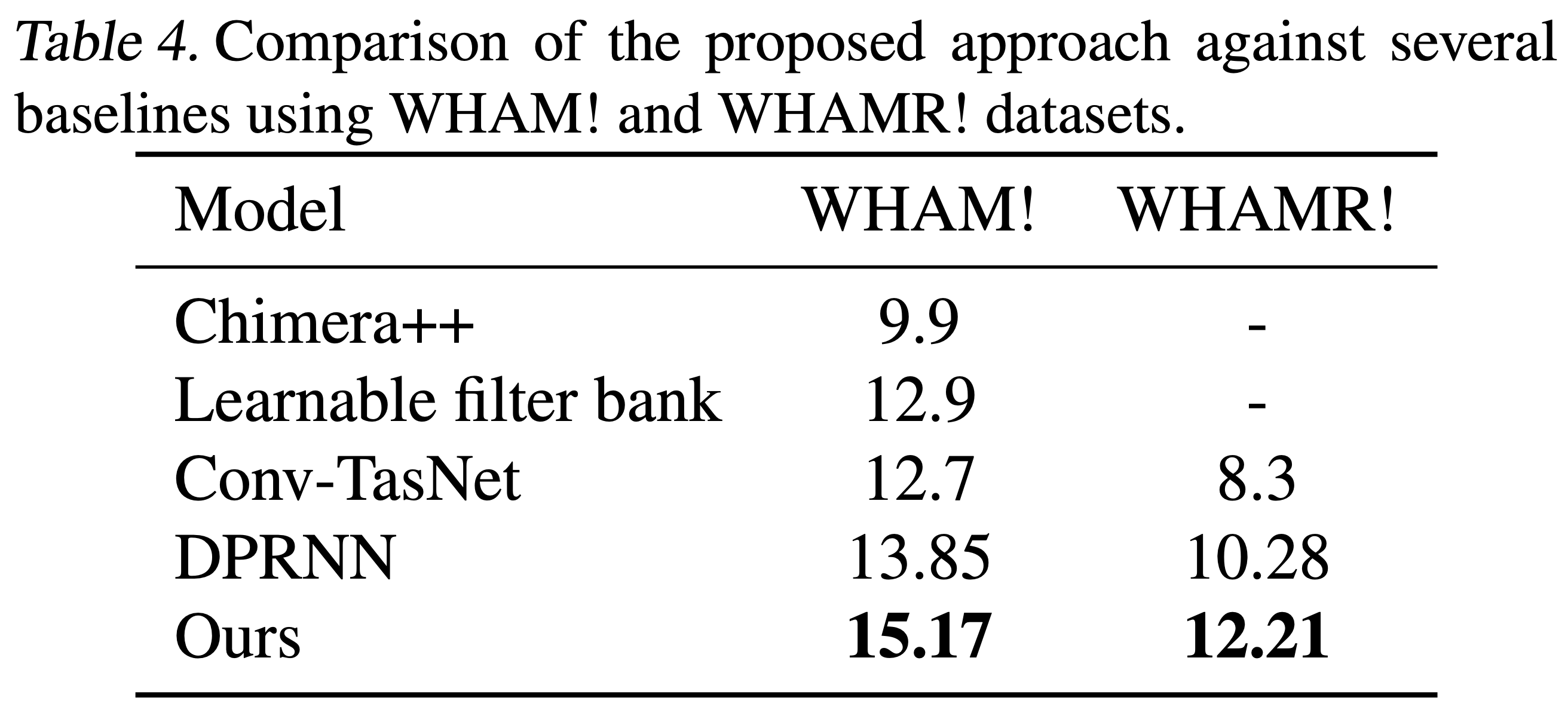
We present a new method for separating a mixed audio sequence, in which multiple voices speak simultaneously. The new method employs gated neural networks that are trained to separate the voices at multiple processing steps, while maintaining the speaker in each output channel fixed. A different model is trained for every number of possible speakers, and a the model with the largest number of speakers is employed to select the actual number of speakers in a given sample. Our method greatly outperforms the current state of the art, which, as we show, is not competitive for more than two speakers.
Link to txt files for 4-5 speaker dataset - Download here
Link to 2-3 speaker dataset [1] - Download from MERL website
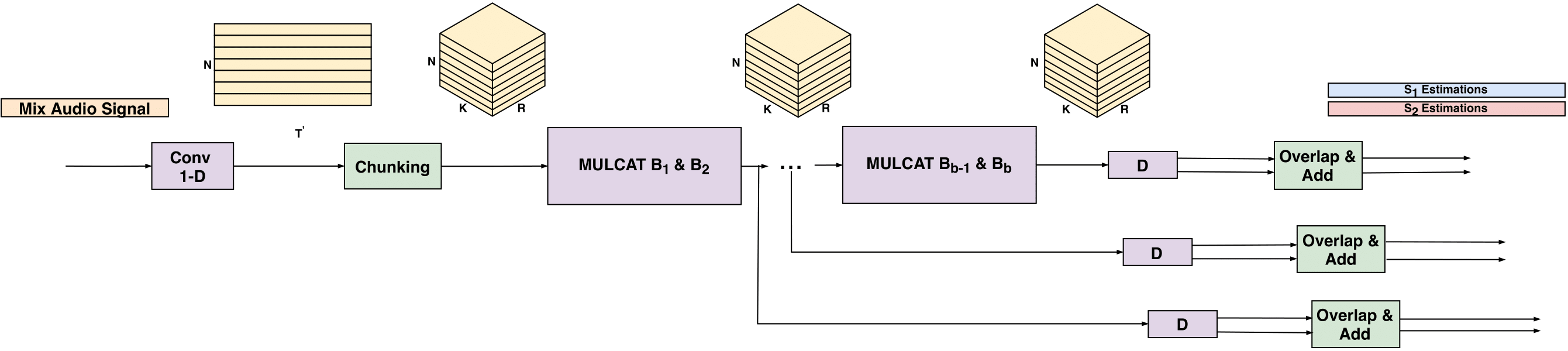
Architecture

Loss Terms